Programming, Life Lessons, and the Power of Forgetfulness
This post is somewhat whimisical, and is spaned by a fascinating article that I read on REgular Expression Pattern matching over at swtch.com .
Regular Expressions are a way of categorising strings of letters and symbols so that you can have a powerful tool for searching text for strings of a particular form, or for insisting that they come in a particular form. For example, you could search a block of text and pull our every set of 7 characters which could be a UK number plate.
Anyway, it turns out that there is an extremely efficient algorithm for doing this matching known as Thompson NFA. This algorithm has been known since almost the beginning of RegEx. It was implemented in early Linux Kernals from the 1970’s. It turns out, that almost no modern language implements this algorithm, instead, they use much much worse versions in their common library functions. How much worse? Well, for a 100 character string Thomson NFA takes 200 microseconds, while Perl would require 10^15 years.
The performance graph is here:

Sorry What? A powerful, fast and efficient algorithm has been known for years, yet most modern programming languages use a vastly inferior version. Why?
It turns out, that communities just forget things. RegEx became what JH Newman called “furniture of the mind”, a concept that you are comfortable with, but don’t really need to understand. When writing their libraries, RegEx functions are just things like maths functions, you implement them because every language should ahve them, but you don’t pay too much attention to them. They are just the boring bricks and mortar of programming.
So Pery, Ruby, Python and Java all shipped with a RegEx algorithm orders of magnitude worse than the best one, and often with more code needed to implement this badly.
Scott Sumner has a theory that Central banks are always fighting the last war, as their domain knowledge is formed when you are studying in your twenties and thirties. People who grew up in the 1970’s are obsessed with inflation. People who grew up in the 1930s were obsessed with deflation. Here is that dynamic in a totally context. Those CS graduates who grew up with RegEx was an interesting and open problem in the 50s and 60s knew about the best algorithms, and implemented in the languages and operating systems of that era. Then it was done, and everyone just used it without understanding it, and the knowledge was `lost’. The next generation created exciting object orientated paradigms and just forgot that this was once an interesting problem with an optimal solution, and just “did the obvious thing”, which turned out to be slow. Then they tried to improve it with a variety of clever tricks like memoisation, but none of that got over the inherent inferiority of the backtracking approach to RegEx matching.
How Much do NGDP expectations matter to the Stock Market?
The inspiration for this post was a brief discussion with a friend, when I attempted to explain why I think of the stock market as a prediction market for NGDP. We might pose the following question, if NGDP expectations were to increase from 5% per year to 6% per year for every year from now to forever, how much would that matter to the stock market?
The short answer is, a lot.
To answer this, lets take a slightly round about route of asking, what is the Net Present Value ,

There is some evidence that we might expect it to be at the higher end of this range going forward due to having more tech with higher profit margins, and more overseas earnings. So lets assume that this is stable at 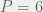

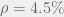

Where we have 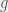
Given the assumptions above, if we assume that everything grows at a stable growth rate (i.e we are ignoring possible path dependency), then

So a 1% increase in NGDP gives about a 40% increase in the stock market, as a handy rule of thumb. No wonder the stock market loves QE!
If we take the EMH seriously, we must conclude that the combination of low TIPS spreads predicting low inflation, and a booming stock market predicting high NGDP, means that we can expect productivity/RGDP to come roaring back any minute now. A market Monetarist argument for Supply Side Optimism. Yes, I’m looking at You Britmouse. 🙂
